
Data Modeling with PostgreSQL
Summary: Modeling user activity data to create a relational database and ETL pipeline in PostgreSQL for a music streaming app.
Check the code here.
Contents:
- 1. Introduction:
- 2. Project datasets
- 3. Schema for Song and Log Data
- 4. Creating Database and Tables
- 5. ETL Processes
1. Introduction:
Modeling user activity data to create a database and ETL pipeline in Postgres for a music streaming app. Defining fact and dimension tables and insert data into new tables.
2. Project datasets
There are two dataset: song dataset and log dataset.
📦data
┣ 📂log_data
┃ ┗ 📂2018
┃ ┃ ┗ 📂11
┃ ┃ ┃ ┣ 📜2018-11-01-events.json
┃ ┃ ┃ ┣ 📜2018-11-02-events.json
┃ ┃ ┃ ┣ ...
┗ 📂song_data
┃ ┗ 📂A
┃ ┃ ┣ 📂A
┃ ┃ ┃ ┣ 📂A
┃ ┃ ┃ ┃ ┣ 📜TRAAAAW128F429D538.json
┃ ┃ ┃ ┃ ┣ 📜TRAAABD128F429CF47.json
┃ ┃ ┃ ┃ ┣ ...
┃ ┃ ┃ ┣ 📂B
┃ ┃ ┃ ┃ ┣ 📜TRAABCL128F4286650.json
┃ ┃ ┃ ┃ ┣ 📜TRAABDL12903CAABBA.json
┃ ┃ ┃ ┃ ┣ ...
┃ ┃ ┃ ┗ 📂C
┃ ┃ ┃ ┃ ┣ 📜TRAACCG128F92E8A55.json
┃ ┃ ┃ ┃ ┣ 📜TRAACER128F4290F96.json
┃ ┃ ┃ ┃ ┣ ...
┃ ┃ ┗ 📂B
┃ ┃ ┃ ┣ 📂A
┃ ┃ ┃ ┃ ┣ 📜TRABACN128F425B784.json
┃ ┃ ┃ ┃ ┣ 📜TRABAFJ128F42AF24E.json
┃ ┃ ┃ ┃ ┣ ...
┃ ┃ ┃ ┣ 📂B
┃ ┃ ┃ ┃ ┣ 📜TRABBAM128F429D223.json
┃ ┃ ┃ ┃ ┣ 📜TRABBBV128F42967D7.json
┃ ┃ ┃ ┃ ┣ ...
┃ ┃ ┃ ┗ 📂C
┃ ┃ ┃ ┃ ┣ 📜TRABCAJ12903CDFCC2.json
┃ ┃ ┃ ┃ ┣ 📜TRABCEC128F426456E.json
┃ ┃ ┃ ┃ ┣ ...
2.1 Song dataset
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song’s track ID. For example, here are filepaths to two files in this dataset.
song_data/A/B/C/TRABCEI128F424C983.json
song_data/A/A/B/TRAABJL12903CDCF1A.json
And below is an example of what a single song file, TRAABJL12903CDCF1A.json, looks like.
{"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
2.2 Log dataset
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations.
The log files in the dataset you’ll be working with are partitioned by year and month. For example, here are filepaths to two files in this dataset.
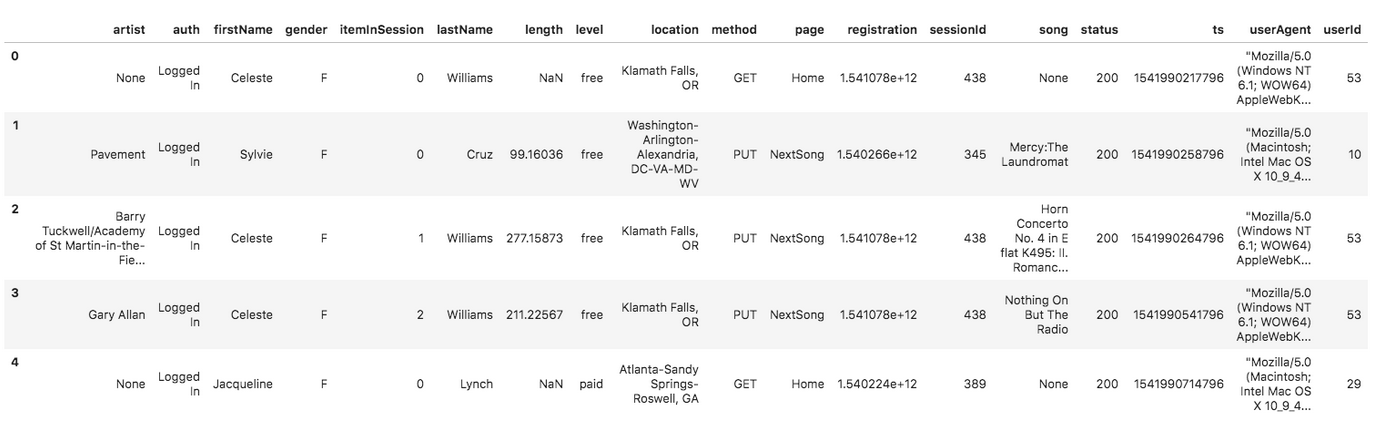
And below is an example of what the data in a log file, 2018-11-12-events.json, looks like.
3. Schema for Song and Log Data
Using the song and log datasets, creating database sparkifydb and creating a star schema for queries on song play analysis. This includes the following tables.
3.1 Fact Table
-
songplays: records in log data associated with song plays
songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent
3.2 Dimension Tables
-
users: users in the app
user_id, first_name, last_name, gender, level -
songs: songs in music database
song_id, title, artist_id, year, duration -
artists: artists in music database
artist_id, name, location, latitude, longitude -
time: timestamps of records in songplays broken down into specific units
start_time, hour, day, week, month, year, weekday
4. Creating Database and Tables
4.1 Queries
Writing SQL queries in sql_queries.py.
sql_queries.py:
# DROP TABLES
songplay_table_drop = "DROP TABLE IF EXISTS songplays"
user_table_drop = "DROP TABLE IF EXISTS users"
song_table_drop = "DROP TABLE IF EXISTS songs"
artist_table_drop = "DROP TABLE IF EXISTS artists"
time_table_drop = "DROP TABLE IF EXISTS time"
# CREATE TABLES
songplay_table_create = ("""
CREATE TABLE IF NOT EXISTS songplays (
songplay_id INTEGER ,
start_time TIMESTAMP NOT NULL,
user_id INTEGER NOT NULL REFERENCES users (user_id),
level VARCHAR,
song_id VARCHAR REFERENCES songs (song_id),
artist_id VARCHAR REFERENCES artists (artist_id),
session_id INTEGER NOT NULL,
location VARCHAR,
user_agent VARCHAR
)
""")
user_table_create = ("""
CREATE TABLE IF NOT EXISTS users (
user_id INTEGER PRIMARY KEY,
first_name VARCHAR NOT NULL,
last_name VARCHAR NOT NULL,
gender CHAR(1),
level VARCHAR NOT NULL
)
""")
song_table_create = ("""
CREATE TABLE IF NOT EXISTS songs (
song_id VARCHAR PRIMARY KEY,
title VARCHAR NOT NULL,
artist_id VARCHAR NOT NULL REFERENCES artists (artist_id),
year INTEGER NOT NULL,
duration NUMERIC (15, 5) NOT NULL
)
""")
artist_table_create = ("""
CREATE TABLE IF NOT EXISTS artists (
artist_id VARCHAR PRIMARY KEY,
name VARCHAR NOT NULL,
location VARCHAR,
latitude NUMERIC,
longitude NUMERIC
)
""")
time_table_create = ("""
CREATE TABLE IF NOT EXISTS time (
start_time TIMESTAMP NOT NULL PRIMARY KEY,
hour NUMERIC NOT NULL,
day NUMERIC NOT NULL,
week NUMERIC NOT NULL,
month NUMERIC NOT NULL,
year NUMERIC NOT NULL,
weekday NUMERIC NOT NULL
)
""")
# INSERT RECORDS
songplay_table_insert = ("""
INSERT INTO songplays (
songplay_id,
start_time,
user_id,
level,
song_id,
artist_id,
session_id,
location,
user_agent
)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
""")
user_table_insert = ("""
INSERT INTO users (
user_id,
first_name,
last_name,
gender,
level
)
VALUES (%s, %s, %s, %s, %s)
ON CONFLICT (user_id)
DO UPDATE
SET level = EXCLUDED.level
""")
song_table_insert = ("""
INSERT INTO songs (
song_id,
title,
artist_id,
year,
duration
)
VALUES (%s, %s, %s, %s, %s)
ON CONFLICT (song_id)
DO NOTHING
""")
artist_table_insert = ("""
INSERT INTO artists (
artist_id,
name,
location,
latitude,
longitude
)
VALUES (%s, %s, %s, %s, %s)
ON CONFLICT (artist_id)
DO NOTHING
""")
time_table_insert = ("""
INSERT INTO time (
start_time,
hour,
day,
week,
month,
year,
weekday
)
VALUES (%s, %s, %s, %s, %s, %s, %s)
ON CONFLICT (start_time)
DO NOTHING
""")
# FIND SONGS
song_select = ("""
SELECT
songs.song_id AS song_id,
songs.artist_id AS artist_id
FROM
songs
JOIN artists ON (songs.artist_id = artists.artist_id)
WHERE
songs.title = %s AND
artists.name = %s AND
songs.duration = %s
""")
# QUERY LISTS
create_table_queries = [time_table_create, user_table_create, artist_table_create, song_table_create, songplay_table_create]
drop_table_queries = [songplay_table_drop, user_table_drop, song_table_drop, artist_table_drop, time_table_drop]
4.2 Creating Database and Table by calling queries
Writing python in create_tables.py to create database sparkifydb and table.
create_tables.py:
import psycopg2
from sql_queries import create_table_queries, drop_table_queries
def create_database():
'''
Create database sparkifydb, connect to this database, return connection and cursor
'''
conn = psycopg2.connect("host=127.0.0.1 port=5432 dbname=de user=postgres password=1992")
conn.set_session(autocommit = True)
cur = conn.cursor()
#create sparkifydb with utf-8 encoding
cur.execute("DROP DATABASE IF EXISTS sparkifydb")
cur.execute("CREATE DATABASE sparkifydb WITH ENCODING 'utf8' TEMPLATE template0")
#close connection to default database
conn.close()
#connect to sparkifydb database
conn = psycopg2.connect("host=127.0.0.1 port=5432 dbname=sparkifydb user=postgres password=1992")
cur = conn.cursor()
return cur, conn
def drop_tables(cur, conn):
'''Drop all tables created on the database'''
for query in drop_table_queries:
cur.execute(query)
conn.commit()
def create_tables(cur, conn):
'''Create tables defined on the sql_queries.py'''
for query in create_table_queries:
cur.execute(query)
conn.commit()
def main():
'''
Function to drop and re-create sparkifydb database and all related tables
how: python create_tables.py
'''
cur, conn = create_database()
drop_tables(cur, conn)
create_tables(cur, conn)
conn.close()
if __name__ == "__main__":
main()
4.3 Check the Created Table
Run test.ipynb to confirm the creation of your tables with the correct columns
-
Create table with command:
%run create_tables.py -
Load sql module in notebook:
%load_ext sqlMake sure the sql module has been installed by
pip install ipython-sql. -
Connect to the created database:
%sql postgresql://postgres:1992@127.0.0.1/sparkifydbExpalain:
%sql postgresql://username:password@address/database_name -
Check the empty database and tables:
5. ETL Processes
Developing ETL processes for each table.
5.1 Importing packages and defining functions
#import packages
import os
import glob
import psycopg2
import pandas as pd
from sql_queries import *
import numpy as np
#connection
conn = psycopg2.connect("host=127.0.0.1 dbname=sparkifydb user=postgres password=1992")
cur = conn.cursor()
#get all files' full path
def get_files(filepath):
all_files = []
for root, dirs, files in os.walk(filepath):
files = glob.glob(os.path.join(root,'*.json'))
for f in files :
all_files.append(os.path.abspath(f))
return all_files
def insert_from_dataframe(df, insert_query):
for i, row in df.iterrows():
cur.execute(insert_query, list(row))
conn.commit()
5.2 Processing song data
Performing ETL on the song dataset to create the songs and artists dimensional tables.
-
Getting song files’ full path
song_files = get_files('data/song_data/') filepath = song_files[0] print(filepath)D:\.......\data\song_data\A\A\A\TRAAAAW128F429D538.json -
Loading data to dataframe
filepath = song_files[0] df = pd.read_json(filepath, lines=True) df_song = df #the first file for idx in range(1, len(song_files)): #second to last file df_song = df_song.append(pd.read_json(song_files[idx], lines=True), ignore_index=True) df_song.head()
Note: in
sql_queries.py, artist_id in songs table refer to artist_id in tableartists, so the tableartistsmust be inserted firstly. -
artistsTable-
Selecting columns for
artist ID, name, location, latitude, and longitude:artist_data = df_song[['artist_id', 'artist_name', 'artist_location', 'artist_latitude', 'artist_longitude']] artist_data = artist_data.drop_duplicates() artist_data = artist_data.replace({np.nan: None}) artist_data.columns = ['artist_id', 'name', 'location', 'latitude', 'longitude'] -
Inserting Record into Artist Table
insert_from_dataframe(artist_data, artist_table_insert) -
Checking the Created
artistsTable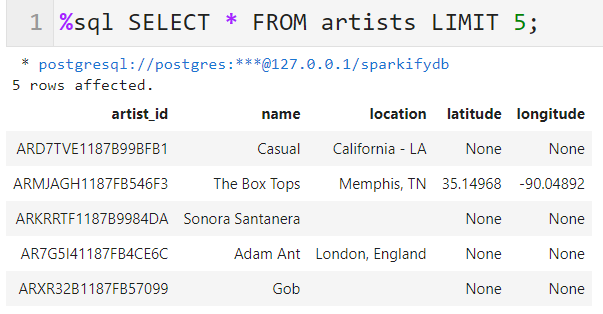
-
-
songsTable-
Selecting columns for
song ID, title, artist ID, year, and durationsong_data = df_song[['song_id', 'title', 'artist_id', 'year', 'duration']] song_data = song_data.drop_duplicates() song_data = song_data.replace({np.nan: None}) -
Inserting Record into
SongTableinsert_from_dataframe(song_data, song_table_insert) -
Checking the Created
songsTable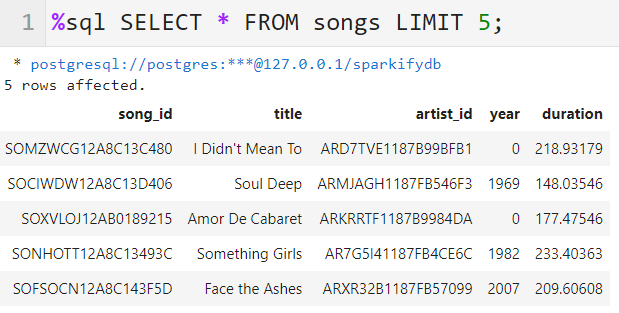
-
5.3 Processing log data
Performing ETL on the second dataset, log_data, to create the time and users dimensional tables, as well as the songplays fact table.
- Getting log files’ full path and load to dataframe
log_files = get_files('data/log_data/')
filepath = log_files[0]
df = pd.read_json(filepath, lines=True)
df_log = df
for idx in range(1, len(log_files)):
df_log = df_log.append(pd.read_json(log_files[idx], lines=True), ignore_index=True)
print(f'df_log size: {df_log.shape}')
df_log.head()
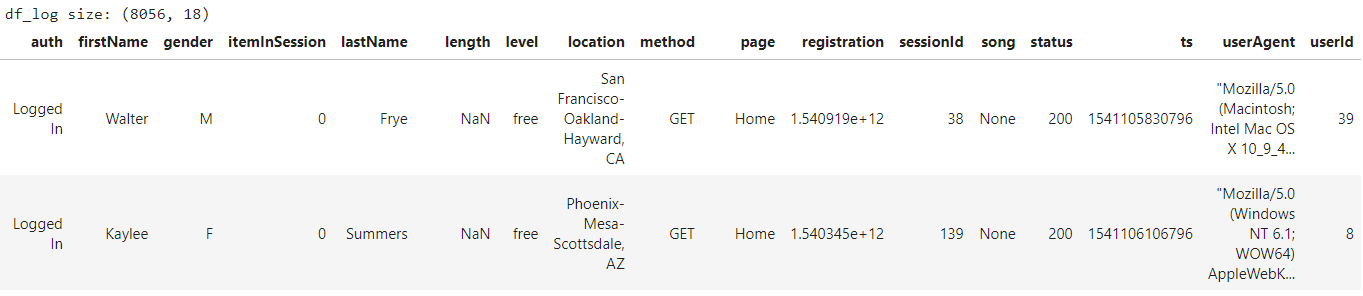
timeTable- Filtering records by
NextSongaction -
Extracting the timestamp,
hour, day, week of year, month, year, and weekdayfrom thetscolumn and set time_data to a list containing these values in orderdf_log = df_log[df_log['page']=='NextSong'] df_log = df_log.replace(np.nan, None) tf = pd.DataFrame({'start_time': pd.to_datetime(df_log['ts'], unit='ms')}) tf['hour'] = tf['start_time'].dt.hour tf['day'] = tf['start_time'].dt.day # tf['week'] = tf['start_time'].dt.week #deprecated tf['week'] = tf['start_time'].dt.isocalendar().week tf['month'] = tf['start_time'].dt.month tf['year'] = tf['start_time'].dt.year tf['weekday'] = tf['start_time'].dt.weekday tf = tf.drop_duplicates() tf.head()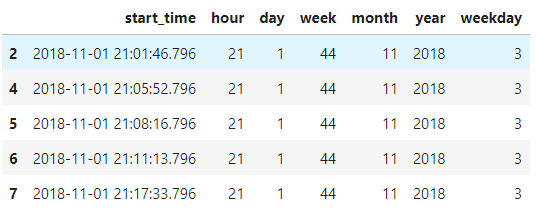
-
Inserting Records into time Table
insert_from_dataframe(tf, time_table_insert) -
Checking the Created
songsTable<p align="center"> <img src="../images/20210412_data_modeling_postgre/time.png" > </p>
- Filtering records by
-
usersTable- Selecting columns for
user ID, first name, last name, gender and leveland set to user_dfuser_df = df_log[['userId', 'firstName', 'lastName', 'gender', 'level']] user_df = user_df.drop_duplicates() user_df = user_df[user_df['userId'] != ''] user_df.columns = ['user_id', 'first_name', 'last_name', 'gender', 'level'] -
Inserting Records into Users Table
insert_from_dataframe(user_df, user_table_insert) -
Checking the Created
songsTable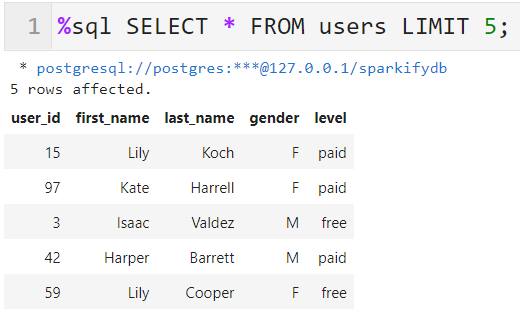
- Selecting columns for
-
songplaysTable- Implementing the song_select query in sql_queries.py to find the song ID and artist ID based on the title, artist name, and duration of a song.
-
Selecting the timestamp, user ID, level, song ID, artist ID, session ID, location, and user agent and set to songplay_data
for index, row in df_log.iterrows(): # get songid and artistid from song and artist tables cur.execute(song_select, (row.song, row.artist, row.length)) results = cur.fetchone() if results: songid, artistid = results else: songid, artistid = None, None # insert songplay record # (songplay_id int, start_time int, user_id int, level text, song_id text, artist_id text, session_id int, location text, user_agent text) # songplay_data = (index, row.ts, int(row.userId), row.level, songid, artistid, row.sessionId, row.location, row.userAgent) songplay_data = (index, pd.to_datetime(row.ts, unit='ms'), int(row.userId), row.level, songid, artistid, row.sessionId, row.location, row.userAgent) cur.execute(songplay_table_insert, songplay_data) conn.commit()-
Checking the Created
songsTable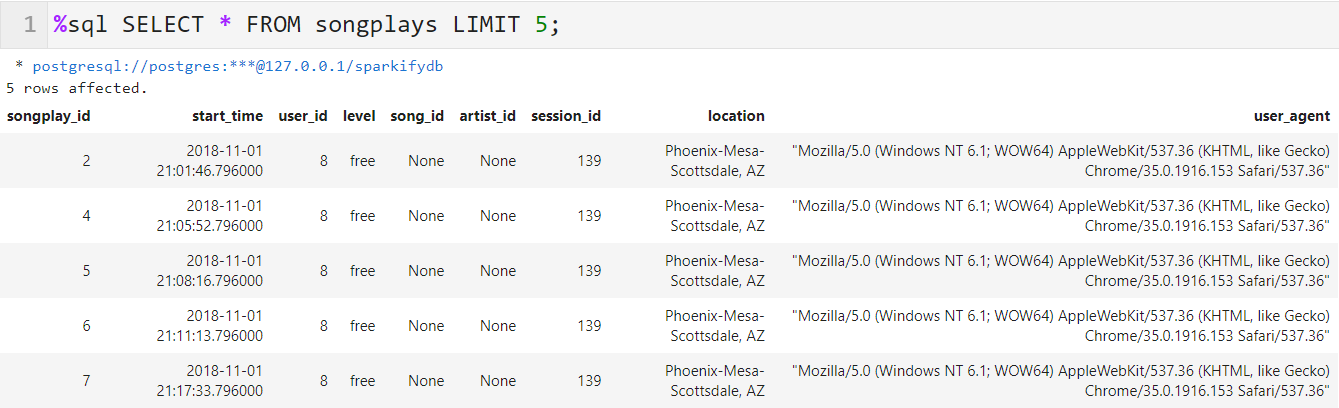
-
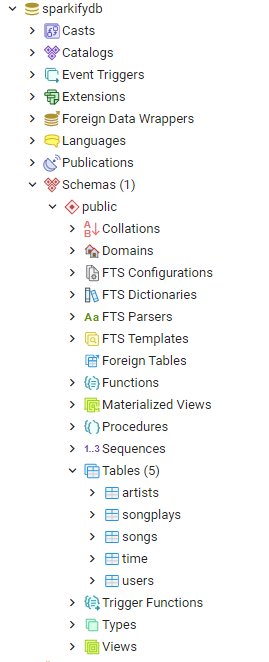
Checking the Created Database in pgAdmin4
Comments