
Data Warehouse with AWS
Summary: Data Warehouse with AWS. Building an ETL pipeline that extracts data from S3, stage them in Redshift, and transform data into a set of dimensional tables for analytics team to continue finding insights in what songs the users are listening to.
Check the code here.
Contents:
- 1. Introduction:
- 2. Project datasets
- 3. Schema for Song and Log Data
- 4.
sql_queries.py - 5. Creating tables
- 6. ETL pipline
1. Introduction:
Data Modeling with Apache Cassandra. Modeling event data to create a non-relational database and ETL pipeline for a music streaming app.
2. Project datasets
There are two dataset: song dataset and log dataset. They reside in S3. Here are the S3 links for each:
- Song data: s3://udacity-dend/song_data
- Log data: s3://udacity-dend/log_data
2.1 Song dataset
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song’s track ID. For example, here are filepaths to two files in this dataset.
song_data/A/B/C/TRABCEI128F424C983.json
song_data/A/A/B/TRAABJL12903CDCF1A.json
And below is an example of what a single song file, TRAABJL12903CDCF1A.json, looks like.
{"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
2.2 Log dataset
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations.
The log files in the dataset you’ll be working with are partitioned by year and month. For example, here are filepaths to two files in this dataset.
And below is an example of what the data in a log file, 2018-11-12-events.json, looks like.
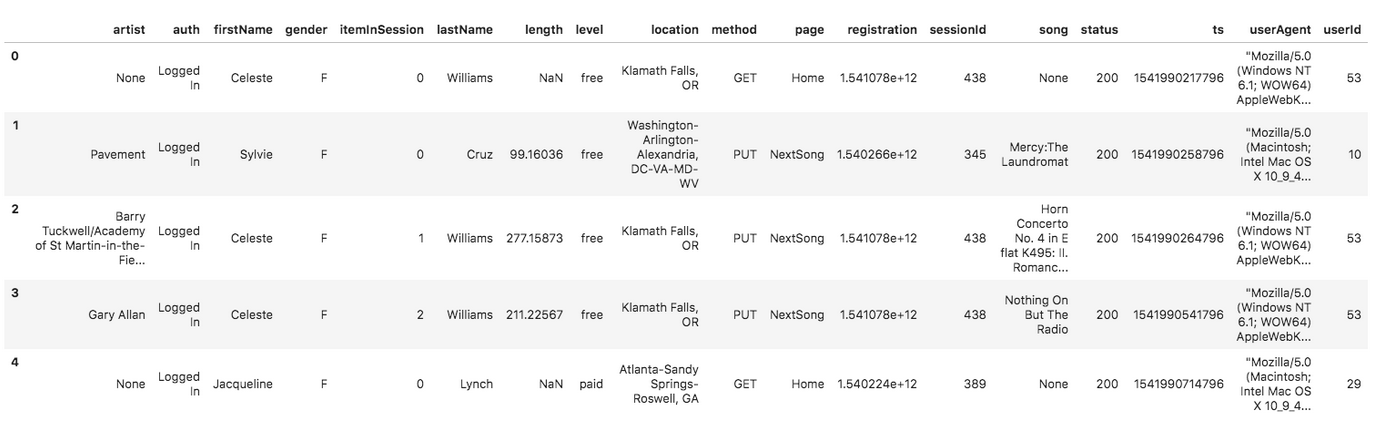
3. Schema for Song and Log Data
Using the song and log datasets, creating database sparkifydb and creating a star schema for queries on song play analysis. This includes the following tables.
3.1 Fact Table
-
songplays: records in log data associated with song plays
songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent
3.2 Dimension Tables
-
users: users in the app
user_id, first_name, last_name, gender, level -
songs: songs in music database
song_id, title, artist_id, year, duration -
artists: artists in music database
artist_id, name, location, latitude, longitude -
time: timestamps of records in songplays broken down into specific units
start_time, hour, day, week, month, year, weekday
4. sql_queries.py
4.1 Read configuration and drop tables
import configparser
# CONFIG
config = configparser.ConfigParser()
config.read('dwh.cfg')
S3_LOG_DATA = config.get('S3', 'LOG_DATA')
S3_LOG_JSONPATH = config.get('S3', 'LOG_JSONPATH')
S3_SONG_DATA = config.get('S3', 'SONG_DATA')
DWH_IAM_ROLE_ARN = config.get("IAM_ROLE", "ARN")
# DROP TABLES
staging_events_table_drop = "DROP TABLE IF EXISTS staging_events;"
staging_songs_table_drop = "DROP TABLE IF EXISTS staging_songs;"
songplay_table_drop = "DROP TABLE IF EXISTS songplays;"
user_table_drop = "DROP TABLE IF EXISTS users;"
song_table_drop = "DROP TABLE IF EXISTS songs;"
artist_table_drop = "DROP TABLE IF EXISTS artists;"
time_table_drop = "DROP TABLE IF EXISTS time;"
4.2 Creating tables
# CREATE TABLES
staging_events_table_create= ("""
CREATE TABLE staging_events (
artist VARCHAR(500),
auth VARCHAR(20),
firstName VARCHAR(500),
gender CHAR(1),
itemInSession INTEGER,
lastName VARCHAR(500),
length DECIMAL(12, 5),
level VARCHAR(10),
location VARCHAR(500),
method VARCHAR(20),
page VARCHAR(500),
registration FLOAT,
sessionId INTEGER,
song VARCHAR(500),
status INTEGER,
ts VARCHAR(50),
userAgent VARCHAR(500),
userId INTEGER
);
""")
staging_songs_table_create = ("""
CREATE TABLE staging_songs (
num_songs INTEGER,
artist_id VARCHAR(20),
artist_latitude DECIMAL(12, 5),
artist_longitude DECIMAL(12, 5),
artist_location VARCHAR(500),
artist_name VARCHAR(500),
song_id VARCHAR(20),
title VARCHAR(500),
duration DECIMAL(15, 5),
year INTEGER
);
""")
songplay_table_create = ("""
CREATE TABLE IF NOT EXISTS songplays (
songplay_id INTEGER IDENTITY(0,1) SORTKEY,
start_time TIMESTAMP NOT NULL,
user_id INTEGER NOT NULL REFERENCES users (user_id),
level VARCHAR(10),
song_id VARCHAR(20) REFERENCES songs (song_id),
artist_id VARCHAR(20) REFERENCES artists (artist_id),
session_id INTEGER NOT NULL,
location VARCHAR(500),
user_agent VARCHAR(500)
)
""")
user_table_create = ("""
CREATE TABLE IF NOT EXISTS users (
user_id INTEGER PRIMARY KEY,
first_name VARCHAR(500) NOT NULL,
last_name VARCHAR(500) NOT NULL,
gender CHAR(1),
level VARCHAR(10) NOT NULL
)
""")
song_table_create = ("""
CREATE TABLE IF NOT EXISTS songs (
song_id VARCHAR(20) PRIMARY KEY,
title VARCHAR(500) NOT NULL SORTKEY,
artist_id VARCHAR NOT NULL DISTKEY REFERENCES artists (artist_id),
year INTEGER NOT NULL,
duration DECIMAL (15, 5) NOT NULL
)
""")
artist_table_create = ("""
CREATE TABLE IF NOT EXISTS artists (
artist_id VARCHAR(20) PRIMARY KEY,
name VARCHAR(500) NOT NULL SORTKEY,
location VARCHAR(500),
latitude DECIMAL(12,6),
longitude DECIMAL(12,6)
)
""")
time_table_create = ("""
CREATE TABLE IF NOT EXISTS time (
start_time TIMESTAMP NOT NULL PRIMARY KEY SORTKEY,
hour NUMERIC NOT NULL,
day NUMERIC NOT NULL,
week NUMERIC NOT NULL,
month NUMERIC NOT NULL,
year NUMERIC NOT NULL,
weekday NUMERIC NOT NULL
)
""")
4.3 Staging tables
# STAGING TABLES
staging_events_copy = ("""
copy staging_events
from {}
region 'us-west-2'
iam_role '{}'
compupdate off statupdate off
format as json {}
timeformat as 'epochmillisecs'
""").format(S3_LOG_DATA, DWH_IAM_ROLE_ARN, S3_LOG_JSONPATH)
staging_songs_copy = ("""
copy staging_songs
from {}
region 'us-west-2'
iam_role '{}'
compupdate off statupdate off
format as json 'auto'
""").format(S3_SONG_DATA, DWH_IAM_ROLE_ARN)
4.4 Final tables
# FINAL TABLES
songplay_table_insert = ("""
INSERT INTO songplays (start_time, user_id, level, song_id, artist_id, session_id, location, user_agent)
SELECT DISTINCT
TIMESTAMP 'epoch' + ts/1000 * INTERVAL '1 second' AS start_time,
e.userId as user_id,
e.level,
s.song_id AS song_id,
s.artist_id AS artist_id,
e.sessionId AS session_id,
e.location AS location,
e.userAgent AS user_agent
FROM
staging_events e, staging_songs s
WHERE
e.page = 'NextSong' AND
e.song = s.title AND
e.userId NOT IN (
SELECT DISTINCT
s2.user_id
FROM
songplays s2
WHERE
s2.user_id = e.userId AND
s2.session_id = e.sessionId
)
""")
user_table_insert = ("""
INSERT INTO users (user_id, first_name, last_name, gender, level)
SELECT DISTINCT
userId AS user_id,
firstName AS first_name,
lastName AS last_name,
gender,
level
FROM
staging_events
WHERE
page = 'NextSong' AND
user_id NOT IN (SELECT DISTINCT user_id FROM users)
""")
song_table_insert = ("""
INSERT INTO songs (song_id, title, artist_id, year, duration)
SELECT DISTINCT
song_id,
title,
artist_id,
year,
duration
FROM
staging_songs
WHERE
song_id NOT IN (SELECT DISTINCT song_id FROM songs)
""")
artist_table_insert = ("""
INSERT INTO artists (artist_id, name, location, latitude, longitude)
SELECT DISTINCT
artist_id,
artist_name AS name,
artist_location AS location,
artist_latitude AS latitude,
artist_longitude AS longitude
FROM
staging_songs
WHERE
artist_id NOT IN (SELECT DISTINCT artist_id FROM artists)
""")
time_table_insert = ("""
INSERT INTO time (start_time, hour, day, week, month, year, weekday)
SELECT
ts AS start_time,
EXTRACT(hr FROM ts) AS hour,
EXTRACT(d FROM ts) AS day,
EXTRACT(w FROM ts) AS week,
EXTRACT(mon FROM ts) AS month,
EXTRACT(yr FROM ts) AS year,
EXTRACT(weekday FROM ts) AS weekday
FROM (
SELECT DISTINCT TIMESTAMP 'epoch' + ts/1000 *INTERVAL '1 second' as ts
FROM staging_events s
)
WHERE
start_time NOT IN (SELECT DISTINCT start_time FROM time)
""")
analytical_queries = [
'SELECT COUNT(*) AS total FROM artists',
'SELECT COUNT(*) AS total FROM songs',
'SELECT COUNT(*) AS total FROM time',
'SELECT COUNT(*) AS total FROM users',
'SELECT COUNT(*) AS total FROM songplays'
]
analytical_query_titles = [
'Artists table count',
'Songs table count',
'Time table count',
'Users table count',
'Song plays table count'
]
4.5 Query list
# QUERY LISTS
create_table_queries = [
staging_events_table_create,
staging_songs_table_create,
time_table_create,
user_table_create,
artist_table_create,
song_table_create,
songplay_table_create
]
drop_table_queries = [staging_events_table_drop, staging_songs_table_drop, songplay_table_drop, user_table_drop, song_table_drop, artist_table_drop, time_table_drop]
copy_table_order = ['staging_events', 'staging_songs']
copy_table_queries = [staging_events_copy, staging_songs_copy]
insert_table_order = ['artists', 'songs', 'time', 'users', 'songplays']
insert_table_queries = [artist_table_insert, song_table_insert, time_table_insert, user_table_insert, songplay_table_insert]
5. Creating tables
import configparser
import psycopg2
from sql_queries import create_table_queries, drop_table_queries
def drop_tables(cur, conn):
"""
Drop all tables
:param cur:
:param conn:
:return:
"""
for query in drop_table_queries:
cur.execute(query)
conn.commit()
def create_tables(cur, conn):
"""
Create all tables
:param cur:
:param conn:
:return:
"""
for query in create_table_queries:
cur.execute(query)
conn.commit()
def main():
config = configparser.ConfigParser()
config.read('dwh.cfg')
conn = psycopg2.connect("host={} dbname={} user={} password={} port={}".format(*config['CLUSTER'].values()))
cur = conn.cursor()
drop_tables(cur, conn)
create_tables(cur, conn)
conn.close()
if __name__ == "__main__":
main()
6. ETL pipline
import configparser
import psycopg2
from sql_queries import copy_table_order, copy_table_queries, insert_table_order, insert_table_queries
def load_staging_tables(cur, conn):
"""
Load data from the logs to the staging tables
:param cur: The cursor of the connection
:param conn: The connection itself
:return:None
"""
idx = 0
for query in copy_table_queries:
print("Copying data into {}...".format(copy_table_order[idx]))
cur.execute(query)
conn.commit()
idx = idx + 1
print(" [DONE] ")
def insert_tables(cur, conn):
"""
Translate/insert data from the staging tables to the analytical tables
:param cur: The cursor of the connection
:param conn: The connection itself
:return:None
"""
idx = 0
for query in insert_table_queries:
print("Inserting data into {}...".format(insert_table_order[idx]))
cur.execute(query)
conn.commit()
idx = idx + 1
print(" [DONE] ")
def main():
config = configparser.ConfigParser()
config.read('dwh.cfg')
conn = psycopg2.connect("host={} dbname={} user={} password={} port={}".format(*config['CLUSTER'].values()))
cur = conn.cursor()
load_staging_tables(cur, conn)
insert_tables(cur, conn)
conn.close()
if __name__ == "__main__":
main()
Comments