
Data Modeling with Apache Cassandra
Summary: Data modeling with Apache Cassandra. Modeling event data to create a non-relational database and ETL pipeline for a music streaming app.
Check the code here.
Contents:
- 1. Introduction:
- 2. Project datasets
- 3. Importing packages and getting filepaths
- 4. Loading all data to one csv file
- 5. Creating a Cluster and Keyspace
- 6.
session_itemTable - 7.
user_sessionTable - 8.
user_songTable - 9. Dropping tables and close sessions
1. Introduction:
Data Modeling with Apache Cassandra. Modeling event data to create a non-relational database and ETL pipeline for a music streaming app.
2. Project datasets
In this project, the dataset event_data will be used. The directory of CSV files partitioned by date. Here are examples of filepaths to two files in the dataset:
event_data/2018-11-08-events.csv
event_data/2018-11-09-events.csv
3. Importing packages and getting filepaths
# Import Python packages
import pandas as pd
import cassandra
import re
import os
import glob
import numpy as np
import json
import csv
# checking current working directory
print(f"Current working directory : {os.getcwd()}")
# Get current folder and subfolder event data
filepath = os.getcwd() + '/event_data'
# Create a list of files and collect each filepath
for root, dirs, files in os.walk(filepath):
# join the file path and roots with the subdirectories using glob
file_path_list = glob.glob(os.path.join(root,'*'))
4. Loading all data to one csv file
# initiating an empty list of rows that will be generated from each file
full_data_rows_list = []
# for every filepath in the file path list
for f in file_path_list:
# reading csv file
with open(f, 'r', encoding = 'utf8', newline='') as csvfile:
# creating a csv reader object
csvreader = csv.reader(csvfile)
next(csvreader)
# extracting each data row one by one and append it
for line in csvreader:
full_data_rows_list.append(line)
print(f"Total rows : {len(full_data_rows_list)}")
print(f"Sample data:\n {full_data_rows_list[:5]}")
# creating a smaller event data csv file called event_datafile_full csv that will be used to insert data into the \
# Apache Cassandra tables
csv.register_dialect('myDialect', quoting=csv.QUOTE_ALL, skipinitialspace=True)
with open('event_datafile_new.csv', 'w', encoding = 'utf8', newline='') as f:
writer = csv.writer(f, dialect='myDialect')
writer.writerow(['artist','firstName','gender','itemInSession','lastName','length',\
'level','location','sessionId','song','userId'])
for row in full_data_rows_list:
if (row[0] == ''):
continue
writer.writerow((row[0], row[2], row[3], row[4], row[5], row[6], row[7], row[8], row[12], row[13], row[16]))
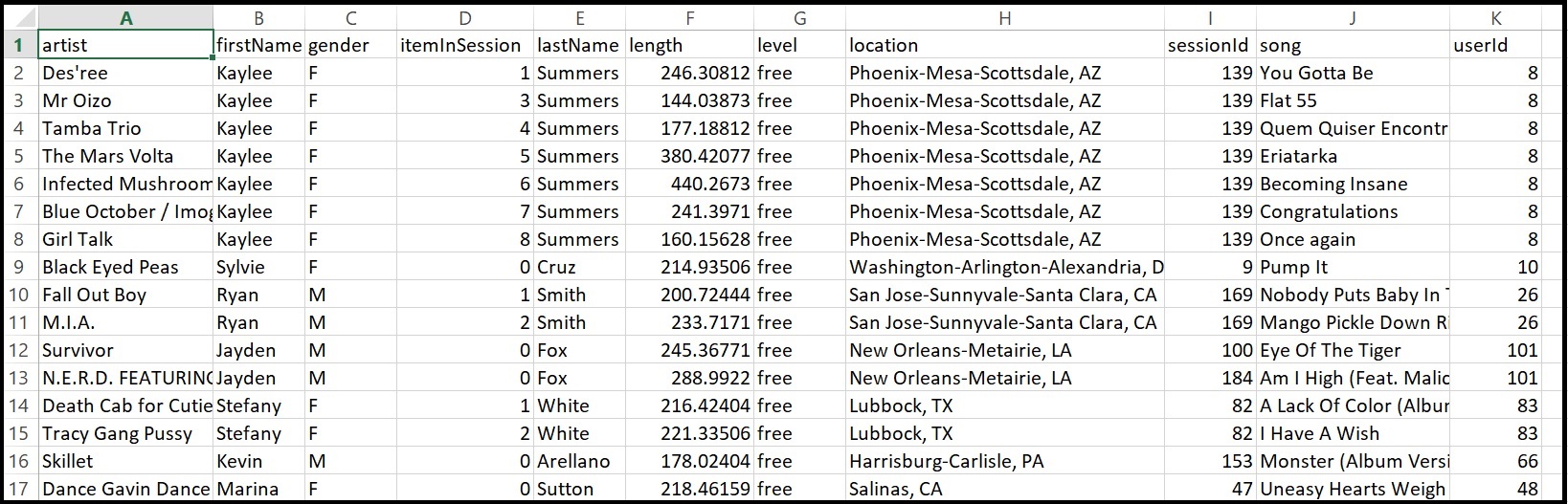
All data will be saved to csv file event_datafile_new.csv, it looks like:
5. Creating a Cluster and Keyspace
-
Creating a Cluster
# This should make a connection to a Cassandra instance your local machine # (127.0.0.1) from cassandra.cluster import Cluster try: cluster = Cluster(['127.0.0.1']) session = cluster.connect() print("Connection Established !!") except Exception as e: print(f"Connection Failed !! Error : {e}") -
Creating Keyspace
keyspace_query = """CREATE KEYSPACE IF NOT EXISTS sparkify with REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 } """ try: session.execute(keyspace_query) except Exception as e: print(f"Failed to create keyspace!! Error : {e}") -
Setting Keyspace
# Setting KEYSPACE to the keyspace specified above session.set_keyspace('sparkify')6.
session_itemTable -
Creating table
session_item# Creating table create_query1 = """CREATE TABLE IF NOT EXISTS session_item (artist text, song text, length float, sessionId int, itemInSession int, PRIMARY KEY (sessionId, itemInSession))""" try: session.execute(create_query1) print("Table Created!!") except Exception as e: print(f"Table creation failed!! Error : {e}") -
Inserting data to table
session_item# Using the event file file = 'event_datafile_new.csv' # Reading csv file and inserting rows into cassandra tables. with open(file, encoding = 'utf8') as f: csvreader = csv.reader(f) next(csvreader) # skip header for line in csvreader: query = "INSERT INTO session_item (artist, song, length, sessionId, itemInSession) " query = query + " VALUES (%s, %s, %s, %s, %s) " session.execute(query, (line[0], line[10], float(line[5]), int(line[8]), int(line[3])) ) -
Selecting data from the table
select_query1 = "SELECT artist, song, length FROM session_item where sessionId = 338 and itemInSession = 4" try: rows = session.execute(select_query1) except Exception as e: print(e) for row in rows: print(row)Row(artist='Faithless', song='50', length=495.30731201171875)
7. user_session Table
-
Creating table
user_sessioncreate_query2 = """CREATE TABLE IF NOT EXISTS user_session (sessionId int, userId int, artist text, song text, firstName text, lastName text, itemInSession int, PRIMARY KEY ((sessionId, userId), itemInSession)) WITH CLUSTERING ORDER BY (itemInSession ASC) """ try: session.execute(create_query2) print("Table Created!!") except Exception as e: print(f"Table creation failed!! Error : {e}") -
Inserting data to table
user_sessionfile = 'event_datafile_new.csv' with open(file, encoding = 'utf8') as f: csvreader = csv.reader(f) next(csvreader) # skip header for line in csvreader: query = "INSERT INTO user_session (sessionId, userId, artist, song, firstName, lastName, itemInSession) " query = query + " VALUES (%s, %s, %s, %s, %s, %s, %s) " session.execute(query, (int(line[8]), int(line[10]), line[0], line[9], line[1], line[4], int(line[3]) ) ) -
Selecting data from the table
select_query2 = "SELECT artist, song, firstName, lastName FROM user_session where sessionId = 182 and userId = 10" try: rows = session.execute(select_query2) except Exception as e: print(e) for row in rows: print(row)Row(artist='Down To The Bone', song="Keep On Keepin' On", firstname='Sylvie', lastname='Cruz') Row(artist='Three Drives', song='Greece 2000', firstname='Sylvie', lastname='Cruz') Row(artist='Sebastien Tellier', song='Kilometer', firstname='Sylvie', lastname='Cruz') Row(artist='Lonnie Gordon', song='Catch You Baby (Steve Pitron & Max Sanna Radio Edit)', firstname='Sylvie', lastname='Cruz')
8. user_song Table
-
Creating table
user_songcreate_query3 = """CREATE TABLE IF NOT EXISTS user_song (song text, userId int, firstName text, lastName text, PRIMARY KEY ((song), userId))""" try: session.execute(create_query3) print("Table Created!!") except Exception as e: print(f"Table creation failed!! Error : {e}") -
Inserting data to table
user_songfile = 'event_datafile_new.csv' with open(file, encoding = 'utf8') as f: csvreader = csv.reader(f) next(csvreader) # skip header for line in csvreader: query = "INSERT INTO user_song (song, userId, firstName, lastName) " query = query + " VALUES (%s, %s, %s, %s) " session.execute(query, ( line[9], int(line[10]), line[1], line[4] ) ) -
Selecting data from the table
select_query2 = "SELECT song, firstName, lastName FROM user_song where song = 'All Hands Against His Own'" try: rows = session.execute(select_query2) except Exception as e: print(e) for row in rows: print(row)Row(song='All Hands Against His Own', firstname='Jacqueline', lastname='Lynch') Row(song='All Hands Against His Own', firstname='Tegan', lastname='Levine') Row(song='All Hands Against His Own', firstname='Sara', lastname='Johnson')
9. Dropping tables and close sessions
-
Droping tables
session.execute("DROP TABLE IF EXISTS sparkify.session_item") session.execute("DROP TABLE IF EXISTS sparkify.user_session") session.execute("DROP TABLE IF EXISTS sparkify.user_song") -
Closing sessions
session.shutdown() cluster.shutdown()
Comments