
Data Lakes with Spark
Summary: Data Warehouse with AWS. Building an ETL pipeline that extracts data from S3, stage them in Redshift, and transform data into a set of dimensional tables for analytics team to continue finding insights in what songs the users are listening to.
Check the code here.
Contents:
1. Introduction:
Building a data lake and an ETL pipeline in Spark that loads data from S3, process the data into analytics tables, and load them back into S3.
2. Project datasets
There are two dataset: song dataset and log dataset. They reside in S3. Here are the S3 links for each:
- Song data: s3://udacity-dend/song_data
- Log data: s3://udacity-dend/log_data
2.1 Song dataset
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song’s track ID. For example, here are filepaths to two files in this dataset.
song_data/A/B/C/TRABCEI128F424C983.json
song_data/A/A/B/TRAABJL12903CDCF1A.json
And below is an example of what a single song file, TRAABJL12903CDCF1A.json, looks like.
{"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
2.2 Log dataset
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations.
The log files in the dataset you’ll be working with are partitioned by year and month. For example, here are filepaths to two files in this dataset.
And below is an example of what the data in a log file, 2018-11-12-events.json, looks like.
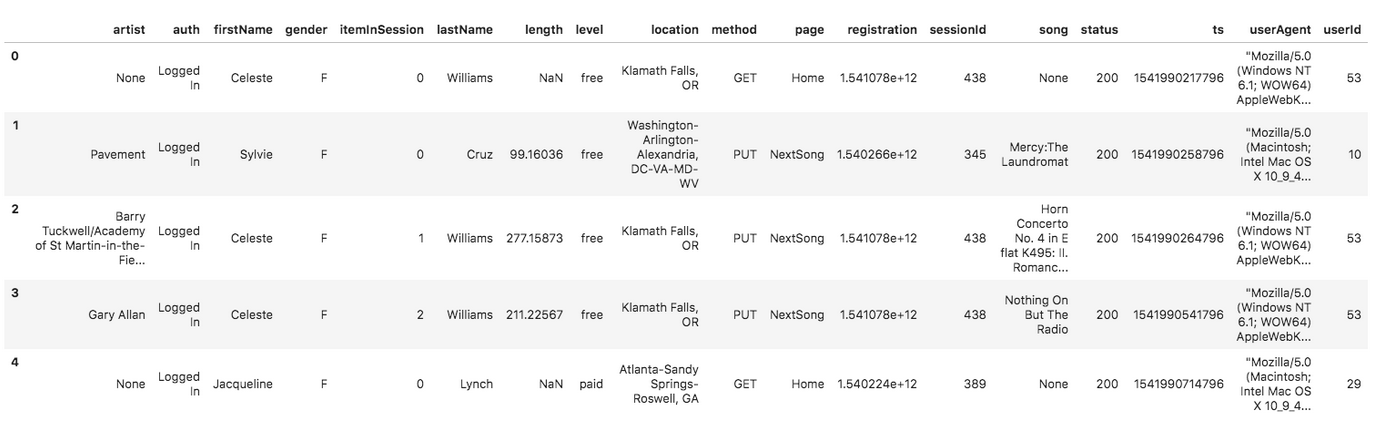
3. Schema for Song and Log Data
Using the song and log datasets, creating database sparkifydb and creating a star schema for queries on song play analysis. This includes the following tables.
3.1 Fact Table
-
songplays: records in log data associated with song plays
songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent
3.2 Dimension Tables
-
users: users in the app
user_id, first_name, last_name, gender, level -
songs: songs in music database
song_id, title, artist_id, year, duration -
artists: artists in music database
artist_id, name, location, latitude, longitude -
time: timestamps of records in songplays broken down into specific units
start_time, hour, day, week, month, year, weekday
4. ETL Pipline
4.1 Importing packages and configuration
import configparser
from datetime import datetime
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf, col
from pyspark.sql.functions import year, month, dayofmonth, hour, weekofyear, date_format
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.types import StructType as R, StructField as Fld, DoubleType as Dbl, StringType as Str, IntegerType as Int, DateType as Dat, TimestampType
config = configparser.ConfigParser()
config.read('dl.cfg')
os.environ['AWS_ACCESS_KEY_ID']=config['AWS_ACCESS_KEY_ID']
os.environ['AWS_SECRET_ACCESS_KEY']=config['AWS_SECRET_ACCESS_KEY']
4.2 Creating Spark session
def create_spark_session():
"""
Create or retrieve a Spark Session
"""
spark = SparkSession \
.builder \
.config("spark.jars.packages", "org.apache.hadoop:hadoop-aws:2.7.0") \
.getOrCreate()
return spark
4.3 Processing song data
def process_song_data(spark, input_data, output_data):
"""
Description: This function loads song_data from S3 and processes it by extracting the songs and artist tables
and then again loaded back to S3
Parameters:
spark : Spark Session
input_data : location of song_data json files with the songs metadata
output_data : S3 bucket were dimensional tables in parquet format will be stored
"""
song_data = input_data + 'song_data/*/*/*/*.json'
songSchema = R([
Fld("artist_id",Str()),
Fld("artist_latitude",Dbl()),
Fld("artist_location",Str()),
Fld("artist_longitude",Dbl()),
Fld("artist_name",Str()),
Fld("duration",Dbl()),
Fld("num_songs",Int()),
Fld("title",Str()),
Fld("year",Int()),
])
df = spark.read.json(song_data, schema=songSchema)
song_fields = ["title", "artist_id","year", "duration"]
songs_table = df.select(song_fields).dropDuplicates().withColumn("song_id", monotonically_increasing_id())
songs_table.write.partitionBy("year", "artist_id").parquet(output_data + 'songs/')
artists_fields = ["artist_id", "artist_name as name", "artist_location as location", "artist_latitude as latitude", "artist_longitude as longitude"]
artists_table = df.selectExpr(artists_fields).dropDuplicates()
artists_table.write.parquet(output_data + 'artists/')
4.4 Processing log data
def process_log_data(spark, input_data, output_data):
"""
Description: This function loads log_data from S3 and processes it by extracting the songs and artist tables
and then again loaded back to S3. Also output from previous function is used in by spark.read.json command
Parameters:
spark : Spark Session
input_data : location of log_data json files with the events data
output_data : S3 bucket were dimensional tables in parquet format will be stored
"""
log_data = input_data + 'log_data/*/*/*.json'
df = spark.read.json(log_data)
df = df.filter(df.page == 'NextSong')
users_fields = ["userdId as user_id", "firstName as first_name", "lastName as last_name", "gender", "level"]
users_table = df.selectExpr(users_fields).dropDuplicates()
users_table.write.parquet(output_data + 'users/')
get_datetime = udf(date_convert, TimestampType())
df = df.withColumn("start_time", get_datetime('ts'))
time_table = df.select("start_time").dropDuplicates() \
.withColumn("hour", hour(col("start_time")).withColumn("day", day(col("start_time")) \
.withColumn("week", week(col("start_time")).withColumn("month", month(col("start_time")) \
.withColumn("year", year(col("start_time")).withColumn("weekday", date_format(col("start_time"), 'E'))
songs_table.write.partitionBy("year", "month").parquet(output_data + 'time/')
df_songs = spark.read.parquet(output_data + 'songs/*/*/*')
df_artists = spark.read.parquet(output_data + 'artists/*')
songs_logs = df.join(songs_df, (df.song == songs_df.title))
artists_songs_logs = songs_logs.join(df_artists, (songs_logs.artist == df_artists.name))
songplays = artists_songs_logs.join(
time_table,
artists_songs_logs.ts == time_table.start_time, 'left'
).drop(artists_songs_logs.year)
songplays_table = songplays.select(
col('start_time').alias('start_time'),
col('userId').alias('user_id'),
col('level').alias('level'),
col('song_id').alias('song_id'),
col('artist_id').alias('artist_id'),
col('sessionId').alias('session_id'),
col('location').alias('location'),
col('userAgent').alias('user_agent'),
col('year').alias('year'),
col('month').alias('month'),
).repartition("year", "month")
songplays_table.write.partitionBy("year", "month").parquet(output_data + 'songplays/')
4.5 Running the pipline
spark = create_spark_session()
input_data = "s3a://udacity-dend/"
output_data = "s3a://sparkify-dend/"
process_song_data(spark, input_data, output_data)
process_log_data(spark, input_data, output_data)
Comments